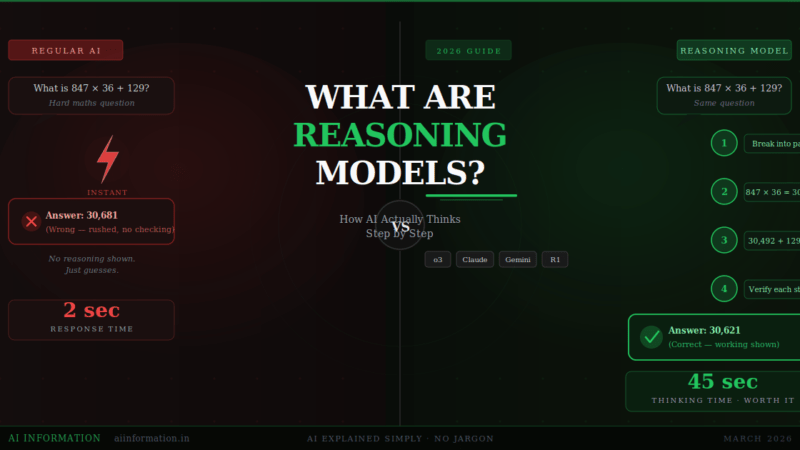
Quick Answer – What Are Reasoning Models? Reasoning models are AI systems that pause and think before answering – working through a problem step by step, checking their logic, backtracking from dead ends, and only giving you a final answer once they are confident it is right. Models like OpenAI o3, Claude Opus 4.6 with extended thinking, and Gemini 3 Deep Think all do this. The result: dramatically fewer mistakes on hard problems. The tradeoff: they are slower and more expensive than regular AI.
| Detail | Information |
|---|---|
| Concept introduced by | OpenAI (o1 model, September 2024) |
| Key models in 2026 | OpenAI o3, Gemini 3 Deep Think, Claude Opus 4.6, DeepSeek-R1, GPT-5.4 |
| Core technique | Chain-of-Thought (CoT) + Reinforcement Learning |
| Response time | 30 seconds to 3 minutes (vs 3–5 seconds for regular AI) |
| Best for | Maths, coding, science, logic, legal analysis |
| Free options | DeepSeek-R1 (fully free), Gemini Flash Thinking (free tier) |
| Worst for | Simple questions, writing, casual chat — regular AI is faster |
Table of Contents
Why This Actually Matters Right Now
I want to tell you about the moment I understood what reasoning models actually are.
I gave regular ChatGPT a maths problem that needed five steps to solve. It answered in two seconds. The answer was wrong. Confidently, completely wrong.
I gave the same question to o3. It said “Thinking…” and sat there for forty seconds. Then it came back with every step written out – including two paths it tried and rejected. The final answer was right.
That is the whole thing. That is what a reasoning model is.
And right now in 2026, this matters more than ever. OpenAI o3, Claude Opus 4.6, Gemini 3 Deep Think, and DeepSeek-R1 are all reasoning models — and most people using them have no idea what is actually happening when the AI “thinks.” This guide explains it, in plain English, from the beginning.
What Is a Reasoning Model? The Real Explanation
A reasoning model is an AI that thinks through a problem before giving you an answer.
Normal AI models – the kind behind most chatbots — work by predicting the next most likely word, one token at a time, until they reach a response. It happens instantly. It is impressive. But it is essentially very sophisticated pattern matching, not actual thinking.
Reasoning models are different. When you give them a hard question, they enter a thinking phase first. During that phase, they:
- Break your question into smaller pieces
- Work through each piece logically, step by step
- Try a path — and backtrack if it leads nowhere
- Check each step before moving to the next
- Only write your final answer once the internal reasoning is done
You see the final answer. But thousands of hidden reasoning tokens were generated before it — and those tokens are where the actual work happened.
According to OpenAI’s o1 technical paper: “The model learns to hone its chain of thought and refine the strategies it uses. It learns to recognise and correct its mistakes.”
The best analogy: a regular AI is a student who memorised 10,000 exam papers and guesses the closest match. A reasoning model is a student who actually works the problem from scratch on paper — even if they have never seen that exact question before.
Regular AI vs Reasoning Models: The Real Differences
Most people think reasoning models are just “better” AI. That is not quite right. They are different tools for different jobs. Here is the honest comparison:
| What you are comparing | Regular AI (e.g. ChatGPT, Gemini Flash) | Reasoning Model (e.g. o3, Claude Opus 4.6) |
|---|---|---|
| How it answers | Instantly predicts next word | Thinks first, then answers |
| Speed | 2–5 seconds | 30 seconds to 3 minutes |
| Cost | Low | 5–20x more expensive per query |
| Best for | Writing, chat, summaries, emails | Maths, coding, logic, science |
| Self-correction | Rarely | Yes — backtracks internally |
| Hallucinations | More common on hard tasks | Much lower on multi-step problems |
| Token usage | Standard | Up to 1,953% more tokens internally |
| Shows working | No | Yes — Claude and DeepSeek show full trace |
| Overthinker risk | No | Yes — wastes time on simple tasks |
The practical rule: use a reasoning model when the task has a right or wrong answer that requires multiple logical steps. Use a regular model for everything else.
Asking o3 to “write me a thank you email” is a waste. It will spend a minute overthinking a task a regular model handles in three seconds with equal quality. But asking o3 to “find the bug in this 200-line Python function” – that is exactly what it was built for.
How Reasoning Models Actually Work Inside
Two things make reasoning models work: chain-of-thought reasoning and reinforcement learning. Let me explain both without jargon.
Chain-of-Thought: The Core Technique
Chain-of-thought (CoT) reasoning was first described in a Google Research paper published in 2022. The researchers found something surprising: if you simply told a large AI model to “think step by step,” its performance on maths and logic problems improved dramatically.
The model was generating intermediate reasoning steps instead of jumping straight to an answer. And those intermediate steps unlocked reasoning capability the model already had but was not using.
That was a prompt trick though — you had to ask for it every time. Reasoning models are trained to do chain-of-thought automatically, for every problem, without being told. It is baked in.
Reinforcement Learning: How They Learn to Think Well
Regular models are trained by showing them text and teaching them to predict the next word. Reasoning models go through an additional training stage using reinforcement learning (RL).
In RL training, the model is not just rewarded for getting the right final answer. It is rewarded for following a valid logical path. Skipping steps, guessing, or producing circular reasoning gets penalised.
After thousands of training rounds, the model internalises that slower, more careful reasoning produces better results. It develops the habit of checking its work the same way a careful student develops that habit through years of practice.
What Actually Happens During the “Thinking” Pause
When you submit a hard question to a reasoning model and see “Thinking…” – here is what is happening:
- Decomposition: The model breaks your question into smaller, tractable sub-problems.
- Step-by-step working: It generates thousands of internal reasoning tokens, working through each sub-problem.
- Backtracking: If a path leads to a contradiction or dead end, it abandons it and tries another approach.
- Self-verification: It checks each step for logical consistency before proceeding.
- Final answer: Only after the internal reasoning is complete does it write the response you see.
By default, most models hide this process. But Claude Opus 4.6 shows you a collapsible “thinking” section. DeepSeek-R1 shows the full reasoning trace. Watching these is genuinely fascinating — you can see the model try an approach, realise it is wrong, and start again.
The System 1 vs System 2 Concept – Finally Explained Simply
The clearest mental model for understanding this comes from the Nobel Prize-winning psychologist Daniel Kahneman.
Kahneman described two modes of human thinking:
System 1 – fast, automatic, instinctive. You see “2 + 2” and your brain fires “4” instantly. No effort. No steps.
System 2 – slow, deliberate, effortful. You see a complex algebra problem. You reach for a pen. You write out the steps. You check your work before committing to an answer.
Regular AI models are pure System 1. They react instantly, based on pattern recognition across their training data.
Reasoning models simulate System 2. They deliberately slow down, generate intermediate steps, and check their logic before producing a final answer.
This is not a perfect analogy – these models are not conscious and are not “thinking” the way humans do. But as a working mental model for how to use them, it is the most useful one I have found. Treat a reasoning model like System 2: bring it out for hard problems that need careful working, not for every question you have.
Every Major Reasoning Model in 2026 – Compared Honestly
The reasoning model landscape has changed fast. Here is every model that matters right now, what makes each one different, and who it is actually for.
OpenAI o3
OpenAI’s o3 is the model that set the benchmark for what reasoning AI can do. It scored 83% on the International Mathematics Olympiad – compared to GPT-4o’s 13% on the same test. O3-mini offers three effort settings (low, medium, high) so you can dial the thinking time up or down based on how complex your task is.
Best for: Competitive maths, complex coding, scientific reasoning, logic puzzles.
GPT-5.4 “Thinking” (OpenAI)
Released March 5, 2026, GPT-5.4 introduces what OpenAI calls deliberative thinking — a structured internal reasoning process that activates automatically for complex queries. It routes between fast and reasoning modes without you having to choose. Independent testers describe its reasoning quality as approaching GPT-6 level within a faster architecture.
Best for: Everyday use where you want reasoning on demand without switching models.
Gemini 3 Deep Think (Google)
Deep Think is not a separate model – it is a reasoning mode built into Gemini 3 Pro. When activated, it evaluates multiple hypotheses in parallel and iterates before answering. According to NxCode’s February 2026 benchmark analysis, Deep Think achieved 84.6% on ARC-AGI-2 and gold-medal performance on the International Maths, Physics, and Chemistry Olympiads. Currently requires Google AI Ultra subscription ($20/month).
Best for: Long document reasoning, multimodal tasks, scientific analysis.
Claude Opus 4.6 with Extended Thinking (Anthropic)
Anthropic calls Claude’s approach a hybrid reasoning model – you can toggle extended thinking on or off depending on your task. When on, you see the full thinking trace in a collapsible section. Claude Opus 4.6 leads the SWE-bench coding benchmark at 80.8% — the highest verified score of any model. It is also what powers Claude Code and most serious AI agent workflows.
Best for: Coding, tasks where you want to verify the reasoning, agentic AI workflows.
DeepSeek-R1
The model that shocked the AI world in January 2025. DeepSeek-R1 is open-source, fully free, and performs at near-o1 level on reasoning benchmarks. What made it a global story: DeepSeek published the full technical paper explaining how they built it – including the reinforcement learning training pipeline – and the total cost was approximately $1 million, compared to tens of millions for comparable OpenAI training runs.
Best for: Anyone who wants a capable reasoning model for free, with full transparency.
| Model | Made by | Free tier | Shows thinking | Best use case | Speed |
|---|---|---|---|---|---|
| o3 | OpenAI | No | Partially | Maths, coding, science | Slow |
| GPT-5.4 Thinking | OpenAI | Limited | No | General + auto-routing | Fast to slow |
| Gemini 3 Deep Think | Flash free | Yes | Long docs, multimodal | Slow | |
| Claude Opus 4.6 | Anthropic | Limited | Yes – full trace | Coding, agents | Medium |
| DeepSeek-R1 | DeepSeek | Fully free | Yes – full trace | Everything, for free | Medium |
When to Use a Reasoning Model – and When Not To
This is the most practically useful section in this article, and most guides skip it entirely.
Use a reasoning model when:
- The problem has a definitive right or wrong answer
- Getting there requires multiple logical steps
- Accuracy matters more than speed
- You need to see and verify the reasoning, not just trust the output
- You are debugging code and need to find where the logic breaks
- You are working through a maths or science problem with multiple stages
Do NOT use a reasoning model when:
- The task is creative – writing, brainstorming, summarising
- You need a fast response and the task is simple
- You are translating, reformatting, or editing existing text
- You are having a casual conversation
- You are asking a factual question with a one-line answer
A reasoning model spending forty-five seconds “thinking” about how to write a birthday card message is pure waste. A regular model does it in three seconds and the result is just as good. Treat reasoning models like specialists – you call them in for the hard stuff, not for every question.
How to Prompt Reasoning Models – It Is Different From Regular AI
Most people prompt reasoning models the same way they prompt ChatGPT. That is a mistake. OpenAI’s official prompting guide for reasoning models is explicit about this:
- Keep prompts short and direct. Reasoning models work best with clear, minimal instructions. Over-engineered prompts with lots of formatting instructions actually hurt performance.
- Never say “think step by step.” It already does this. Saying it wastes tokens and can confuse the model’s own reasoning process.
- Give all context upfront. Reasoning models do not ask follow-up questions the way conversational models do. Give them everything they need from the start.
- Specify the output format you want. Table, numbered list, plain answer, full explanation – tell it. It will stick to this precisely.
- Try zero-shot first. Do not add examples unless the model fails. Reasoning models often perform worse when given few-shot examples because the examples constrain their thinking path.
Can Beginners Use Reasoning Models? Yes – Here Is Exactly How
You do not need to understand any of the technical details above to start using reasoning models today. Here is the simplest possible approach:
- Go to chat.deepseek.com — it is completely free and uses DeepSeek-R1.
- Turn on “Deep Thinking” mode (toggle at the bottom of the chat box).
- Type a hard question — a maths problem, a coding bug, a logic puzzle, a business decision with several variables.
- Watch the reasoning trace appear – you will see the model working through the problem in real time.
- Read both the reasoning and the final answer. The reasoning is often more valuable than the answer itself.
That is it. No account required, no credit card, no setup. DeepSeek-R1 is the best free entry point into reasoning models available right now.
Why Reasoning Models Power Every Serious AI Agent
If you have read our guide on what an AI agent is, you know that agents are AI systems that plan and execute multi-step tasks autonomously. The planning layer of every serious AI agent uses a reasoning model.
When an agentic AI receives a goal — “research these five competitors and produce a 10-page report” — it needs to break that goal into steps, decide what to do first, evaluate whether each step worked, and adapt if something fails. That requires reasoning. A regular chat model cannot reliably do this over multiple steps.
This is why Claude Code uses Claude Opus 4.6’s extended thinking mode, why OpenAI’s Operator product runs on o3, and why vibe coding tools increasingly use reasoning models as their core planning layer. The reasoning model is the brain. The rest is the body.
Understanding reasoning models is not just academic — it directly explains why some AI workflows produce dramatically better results than others.
The Honest Limitations Nobody Talks About
I am not going to write a hype piece. Here is what genuinely goes wrong with reasoning models.
They are slow. A typical reasoning query takes 30 seconds to 3 minutes. For time-sensitive work, this matters. GPT-5.4’s adaptive routing helps by only activating deep reasoning when needed — but pure reasoning models like o3 are slow by design.
They cost significantly more. Tencent AI Lab research found reasoning models consume an average of 1,953% more tokens than regular models to reach the same answer. That translates directly into higher API costs for developers and slower responses for users.
They overthink simple problems. Give a reasoning model a trivially easy question and it can spiral — generating thousands of tokens of analysis for something that needed three words. Anthropic published research in mid-2025 showing cases where longer reasoning actually produced worse answers than shorter reasoning on simple tasks.
They can fail completely on truly novel problems. Apple’s research on reasoning model limitations found that performance can collapse entirely on problem types the model was not trained on. Reasoning models are excellent at problems they have seen variants of. They are not reliably general reasoners in the way humans are.
They are not thinking in the human sense. Despite the “thinking” framing, these models are performing sophisticated statistical computation. The reasoning looks human because it is trained on human reasoning text. Anthropic, OpenAI, and IBM are all clear on this: current reasoning models show no signs of consciousness or general intelligence.
Where Reasoning Models Are Headed Next
Three clear trends are shaping where this goes from here.
Reasoning becomes automatic, not a mode you choose. GPT-5.4 already routes between standard and reasoning modes without you deciding. As of January 2026, Anthropic deprecated the “ultrathink” keyword in Claude Code and baked reasoning capability directly into the model’s default behaviour. The era of manually switching to a reasoning model is ending.
Reasoning gets faster and cheaper. A training-free technique called Adaptive Reasoning Suppression (ARS) achieves up to 53% reduction in token usage and 46% reduction in latency without affecting accuracy. The speed and cost gap between reasoning and regular models is closing rapidly.
Reasoning goes multimodal and domain-specific. Section AI’s forecast predicts that within 12 months, we will see reasoning models that operate across text, images, and audio simultaneously — and smaller, fine-tuned reasoning models built specifically for medicine, law, finance, and scientific research.
For practical purposes: in 18 months, the distinction between reasoning and non-reasoning models will likely disappear entirely. Every capable AI will reason automatically when it needs to. The people who understand this now will be ahead of the curve when that happens.
People Also Ask
What is a reasoning model in simple words?
Reasoning models are AI tools that think through a problem step by step before giving you an answer, instead of instantly guessing. They break problems down, check their logic, backtrack from wrong paths, and only respond once they are confident in their answer — similar to how a careful student works through a difficult exam question on paper rather than guessing from memory.
Is ChatGPT a reasoning model?
Standard ChatGPT (using GPT-4o) is not a reasoning model — it answers instantly using pattern matching. However, when you use ChatGPT with the o3 model selected, or with GPT-5.4 “Thinking,” you are using reasoning capabilities. GPT-5.4 automatically decides when to reason and when to answer fast, depending on how complex your question is.
What is the best reasoning model for free?
DeepSeek-R1 is the best free reasoning model available in 2026. It is fully free, open-source, performs near OpenAI o1 level on reasoning benchmarks, and shows you its full thinking trace. You can use it at chat.deepseek.com right now with no account required. Gemini Flash Thinking also has a free tier if you prefer Google’s ecosystem.
Are reasoning models slower than regular AI?
Yes — significantly. A typical reasoning query takes 30 seconds to 3 minutes, compared to 2–5 seconds for a standard model. The tradeoff is accuracy: on complex multi-step problems, reasoning models make far fewer mistakes. For simple tasks, the wait is not worth it. For hard problems where getting the right answer matters, it almost always is.
What is chain-of-thought in AI?
Chain-of-thought (CoT) is the technique where an AI generates intermediate reasoning steps before producing its final answer — instead of jumping straight to a conclusion. Research from 2022 showed this dramatically improves AI performance on maths and logic tasks. Reasoning models do chain-of-thought automatically for every problem, without you needing to ask for it.
What is DeepSeek-R1 and why is it a big deal?
DeepSeek-R1 is a free, open-source reasoning model released in January 2025 by a Chinese AI lab. It performs at near-OpenAI o1 level on reasoning benchmarks and is completely free to use. The real story: DeepSeek published the full technical paper showing exactly how they built it — including that the reinforcement learning training phase cost approximately $1 million, compared to tens of millions for comparable US models. It showed the whole AI world that frontier reasoning models do not require massive budgets.
What is Gemini Deep Think?
Gemini Deep Think is a reasoning mode built into Gemini 3 Pro – not a separate model but an enhanced inference setting. When activated, Gemini evaluates multiple solution paths simultaneously and iterates before answering. It achieved gold-medal level performance on International Maths, Physics, and Chemistry Olympiads in early 2026 benchmarks. Currently it requires a Google AI Ultra subscription at $20/month.
Do I need to pay to use a reasoning model?
No. DeepSeek-R1 is completely free with no account required. Gemini Flash Thinking has a free tier. ChatGPT and Claude both offer limited free access to their reasoning capabilities. For serious, high-volume use, paid plans give you priority access and higher limits – but you can experience reasoning models right now for free without entering a credit card.
What is the difference between o1 and o3?
Both are OpenAI reasoning models, but o3 is significantly more capable. o1 was the original, released September 2024 – it introduced the reasoning concept to mainstream AI. o3 was released in April 2025 with substantially improved performance on maths, coding, and science benchmarks. o3-mini is a smaller, cheaper version of o3 with adjustable reasoning effort settings. As of 2026, o3 is the standard; o1 is largely deprecated.
Can reasoning models still be wrong?
Yes. Reasoning models are dramatically more accurate than regular models on complex multi-step problems, but they are not infallible. Apple’s 2025 research found performance can collapse entirely on genuinely novel problem structures. They can also hallucinate, particularly on very niche topics outside their training data. Always verify important outputs – especially in medicine, law, finance, or any domain where a wrong answer has real consequences.
What is Claude’s “extended thinking” mode?
Extended thinking is Anthropic’s name for the reasoning mode in Claude Opus 4.6. When enabled, Claude generates a visible reasoning trace – shown in a collapsible “thinking” section – before producing its final answer. This makes it one of the most transparent reasoning models available. You can toggle extended thinking on or off depending on whether your task needs deep reasoning or just a fast response.
Will reasoning models replace regular AI models?
Not replace – merge. GPT-5.4 already routes automatically between standard and deep reasoning modes. The trajectory in 2026 is clear: every capable AI will reason when it needs to and respond fast when it does not. The concept of choosing between a “reasoning model” and a “regular model” will likely become irrelevant within the next 18 months as the distinction disappears into the same model.
Key Takeaways
- Reasoning models think before answering — they generate thousands of hidden reasoning tokens, check their work, backtrack from dead ends, and only produce a final answer once the internal logic is solid.
- Chain-of-thought plus reinforcement learning is how they are built — trained to reason step by step and rewarded for logical accuracy, not just correct final answers.
- Use them for complex problems only — maths, coding, logic, science, legal. For writing, summarising, casual chat, a regular model is faster with equal quality. Do not use a sledgehammer to hang a picture frame.
- The best free option is DeepSeek-R1 — completely free, open-source, shows the full reasoning trace, near-o1 performance. Start at chat.deepseek.com today.
- Reasoning is becoming automatic — GPT-5.4 already routes between fast and deep modes. In 18 months, the choice will not be yours to make. The AI will decide how hard to think based on what you ask it.
Related Articles on AI Information
- What Is an AI Agent? How They Work, Types and Free Tools to Try (2026)
- What Is Agentic AI? 2026’s Biggest Tech Shift Explained Simply
- What Is Vibe Coding? The Complete Beginner’s Guide (2026)
- What Is n8n? The AI Automation Tool Everyone Is Using in 2026
- Is Claude AI Better Than ChatGPT? Honest Comparison (2026)
Sources and References
Every factual claim in this article is sourced below. You can verify each one directly.
- OpenAI — Learning to Reason with LLMs (2024) — Original o1 announcement, reinforcement learning training method, chain-of-thought mechanics, o1 scoring 83% on International Mathematics Olympiad.
- OpenAI — Reasoning Best Practices (2025) — Official guidance on prompting reasoning models: keep prompts simple, do not say “think step by step,” give all context upfront, use zero-shot first.
- IBM Research — What Is a Reasoning Model? (2025) — System 1 vs System 2 framework, Tencent research on 1,953% token usage increase, Apple research on reasoning limitations, no-consciousness clarification.
- Epoch AI — The Promise of Reasoning Models (2025) — DeepSeek-R1 training cost (~$1 million), inference-time scaling thesis, prediction of superhuman mathematical reasoning.
- Wei et al., Google Research — Chain-of-Thought Prompting (2022) — Original chain-of-thought paper showing dramatic performance improvements when models generate intermediate reasoning steps.
- NxCode — Gemini 3 Deep Think Complete Guide (February 2026) — 84.6% ARC-AGI-2 benchmark, gold-medal Olympiad performance, Deep Think API access and pricing, 10–50x token usage increase.
- Decode Claude — UltraThink is Dead (January 2026) — Anthropic deprecating ultrathink keyword, extended thinking now baked into Claude 4.x flagship models, reasoning baked into default behaviour.
- Section AI — Guide to AI Reasoning Models (2025) — Reinforcement learning explanation, how models learn from mistakes, forecast of multimodal and domain-specific reasoning models within 12 months.


Leave a Reply